data146projects
Execute a K-nearest neighbors classification method on the data. What model specification returned the most accurate results? Did adding a distance weight help?
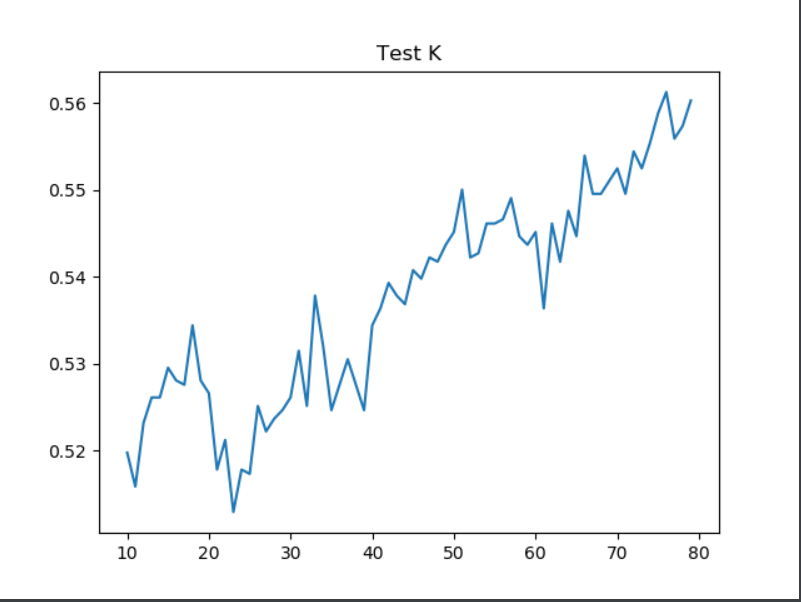
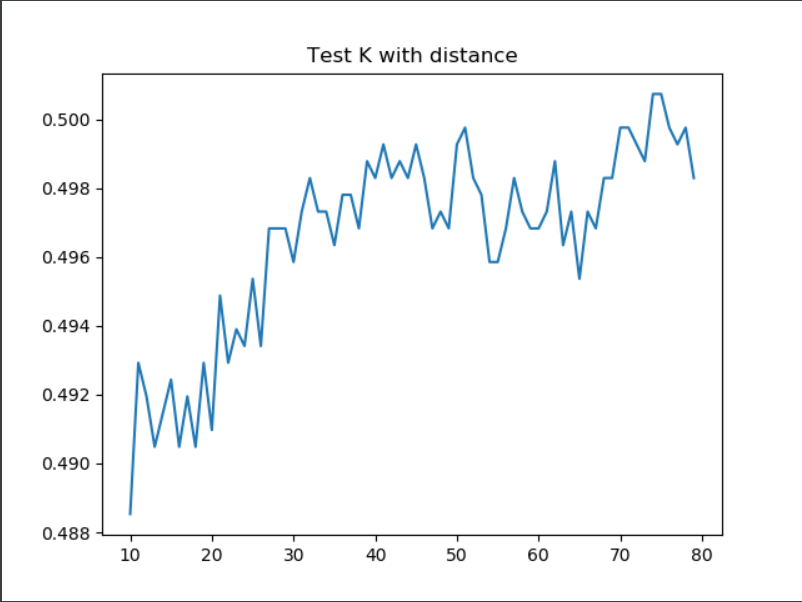
First, I executed a KNN with a range of 10 to 80. This resulted in a max testing score of 0.5519765739385066 at an alpha of 68. After adding distance to the KNN, with a range of 10 to 80, I got a max testing score of 0.5085407515861395 at an alpha of 69. As a result of adding distance weight, the max score decreased significantly, so it did not help.
Execute a logistic regression method on the data. How did this model fair in terms of accuracy compared to K-nearest neighbors?
This model resulted in a training score of 0.5452473958333334, and a testing score of 0.552464616886286. In comparison to the accuracy of K-nearest neighbors, it did slightly better, but only by an incredibly small amount. It was roughly comparable to the accuracy of KNN.
Next execute a random forest model and produce the results. See the number of estimators (trees) to 100, 500, 1000 and 5000 and determine which specification is most likely to return the best model. Also test the minimum number of samples required to split an internal node with a range of values. Also produce results for your four different estimator values by both comparing both standardized and non-standardized (raw) results.
Looking at the data, a random forest model with 1000 estimators is likely to return the best model. That being said, this is only by a very small amount. Most of the scores are very similar in value. When the data is standardized, the accuracy tends to decrease.
After testing the minimum number of samples required to split, I got a max of .5578330893118595 at 20. This was similar to the KNN and logistic regression scores I got before, but higher than the other scores of the random forest model.
| Estimator values and testing results | ||
|---|---|---|
| Estimator | Non-standardized testing | Standardized testing |
| 100 | 0.4992679355783309 | 0.4958516349438751 |
| 500 | 0.4997559785261103 | 0.49633967789165445 |
| 1000 | 0.5017081503172279 | 0.49487554904831627 |
| 5000 | 0.4987798926305515 | 0.4992679355783309 |
Repeat the previous steps after recoding the wealth classes 2 and 3 into a single outcome. Do any of your models improve? Are you able to explain why your results have changed?
KNN: 0.5612493899463152 at a value of 76
KNN with weight: 0.5007320644216691 at a value of 74
Overall, the KNN is very slightly higher than it was before the wealth classes 2 and 3 were merged together. This change is only incredibly minor, however. Also, the score for KNN with weight is lower after the merging of wealth classes 2 and 3, but also only by a small amount. Logical Regression: The model had a training score of 0.5572916666666666, and a testing score of 0.5397755002440214. This is a better training score, but a slightly worse testing score than before merging the two wealth classes.
| Estimator values and testing results | ||
|---|---|---|
| Estimator | Non-standardized testing | Standardized testing |
| 100 | 0.5002440214738897 | 0.5070766227428014 |
| 500 | 0.5007320644216691 | 0.5051244509516838 |
| 1000 | 0.5012201073694486 | 0.5061005368472425 |
| 5000 | 0.49829184968277207 | 0.5104929233772572 |
As before, there is only a slight change, but the models here are greater than they were before the two classes were merged. 1000 estimators still remains the most accurate when it comes to non-standardized testing.
As a result of merging wealth classes 2 and 3 together, in general, my models decreased in accuracy. My results might have changed because having wealth 2 and 3 as separate classes could have been more useful when calculating varying degrees of predicted wealth. That being said, the random forest models all seemed to increase slightly after the wealth classes were recoded. That might be because having less wealth classes could have more positively impacted the efficiency in using trees.
Which of the models produced the best results in predicting wealth of all persons throughout the large West African capital city being described? Support your results with plots, graphs and descriptions of your code and its implementation. You are welcome to incorporate snippets to illustrate an important step, but please do not paste verbose amounts of code within your project report. Avoiding setting a seed essentially guarantees the authenticity of your results. You are welcome to provide a link in your references at the end of your (part 2) Project 5 report.
In general, the models based on data when wealth classes 2 and 3 were not recoded performed the best. This can be seen in comparing the graphs and data listed above, where the models from before recoding repeatedly produce higher results. It can also be seen in the below graphs that compare the K-nearest neighbor for the data before and after recoding the wealth classes. Out of the different models created before the data was recoded, the model that produced the best results at predicting wealth was logistic regression. Most other models produced similar results, but their results were not nearly as high.
Plots of K-nearest neighbor testing (weighted and unweighted):
.PNG)
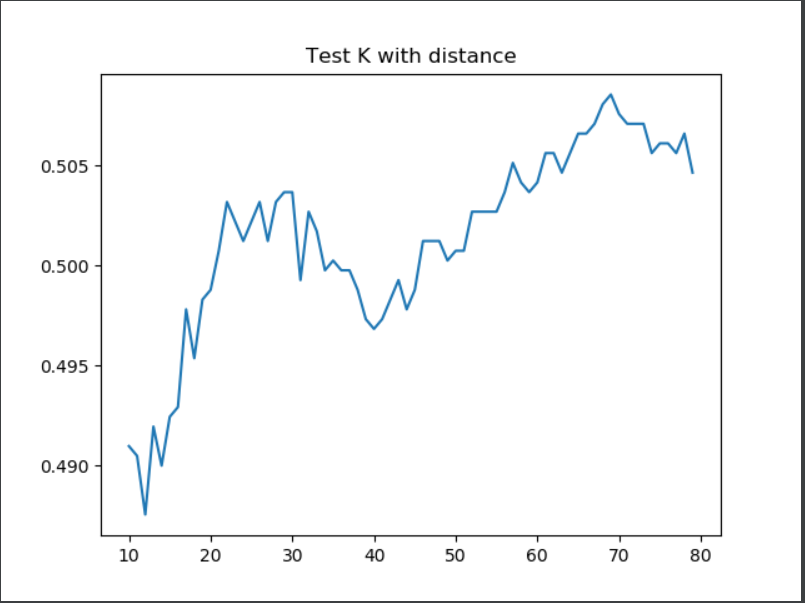
Plots of K-nearest neighbor testing after recoding wealth classes 2 and 3 (weighted and unweighted):