data146projects
Preparing data:
Initially, I imported the data, and used wealthC as the target. Later in this project, I used wealthI. I removed data that contained Nan, or null values. This was fine, as there was enough viable data that this made very little impact on the models. I ended up getting rid of just around 80 values, out of almost 50,000, so this had an insignificant effect. Perform a linear regression and compute the R-Squared Value. Standardize the features and again compute the R-Squared Value. Compare the coefficients from each of the two models and describe how they have changed.
WealthC:
Linear Regression:
MSE: 0.44281007841525305
MSE after standardization: 0.4428116358330327
R-Squared training: 0.7358358668648066
R-Squared testing: 0.7350977596556885
R-Squared training after standardization: 0.7358175988130666
R-Squared testing after standardization: 0.7350931051770687
The way the r-squared values changed before and after standardization is incredibly small. There is practically no significant change in value, and it has an incredibly minimal effect. The only noticeable difference is that the R-squared values for training and testing very slightly decrease after standardization. On the other hand, the coefficients greatly differed as a result of standardization. Practically all of these values changed, suggesting it strongly affected many different individual correlation rates. As a whole, these correlations seem to also vary less in range than they did before.
Before standardization: [ 3.01812923e-02 1.07882853e-02 -5.57603897e-04 8.37880684e-02 4.04701739e-02 6.37198352e-02 -1.40023112e-01 9.99896825e-02 1.85515805e-01 -2.49517259e-01 -2.47122665e-01 -7.30324831e-02 3.09612080e-01 -1.29375995e-01 3.53607318e-01 2.33225714e-01 -1.34364084e-01 -1.92558301e-01 -1.20146711e-01 3.59279100e-02 1.46004504e-01 -1.81932414e-01 1.05944573e-01 4.00186663e-01 1.72822325e-01 2.29943453e-02 1.03043774e-01 -1.15888783e-01 -2.18966624e-01 -2.90949455e-01 -3.83672661e-01 -3.84737293e-01 3.07519898e-01 2.55401258e-02 2.56163113e-01 3.95033383e-01 3.60442298e-01 1.90435535e-01 3.86891012e-01 1.53405264e-01 -2.09042764e-02 5.43122461e-02 -1.27172669e-01 -5.40268677e-01 -5.63637093e-01 -1.58355761e-01 -1.08923385e-01 -2.12578757e-02 -3.26132080e-01 3.26132080e-01 -6.44297719e-02 6.44297719e-02 -2.76390443e-01 4.32693258e-01 6.03439291e-02 4.07576086e-01 -6.37787977e-01 1.35651470e-02 -2.47897601e-01 2.47897601e-01]
After Standardization: [ 1.12516818e-01 5.45138603e-03 -1.09052190e-02 6.91757622e-02 4.27705195e+10 5.02750453e+10 4.46426842e+10 4.59289510e+10 4.90688361e+10 4.58408746e+10 4.57525829e+10 5.08743641e+10 5.02679372e+10 4.95791892e+10 6.74047811e+10 5.86583411e+10 4.44014945e+10 4.35911747e+10 4.75401268e+10 8.79962983e+10 1.33191584e+11 1.44277596e+11 1.62021654e+10 1.62898123e+10 2.97209137e+10 3.45804794e+10 1.78462847e+11 8.79824149e+10 3.70473602e+10 5.51589371e+10 1.56648361e+11 1.15859703e+10 1.92521007e+10 3.05169611e+10 3.93893864e+10 3.42202395e+10 1.49394480e+11 5.76819981e+10 2.78762929e+10 1.07757492e+10 2.25264110e+11 1.36085175e+11 1.46929051e+11 2.84738583e+11 1.16875748e+10 1.69330127e+10 1.07363095e+11 2.21635665e+10 -1.20425207e+10 -1.20425207e+10 -3.89052548e+10 -3.89052548e+10 -1.05937813e+10 -4.94030460e+09 -9.62901871e+09 -2.08266264e+11 -2.09670077e+11 -3.05541141e+10 -3.51666090e+10 -3.51666090e+10]
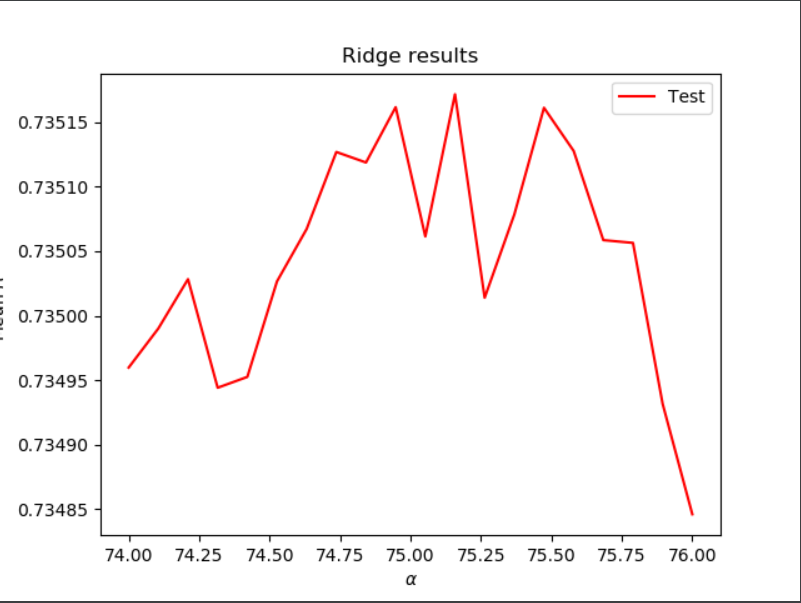
Ridge Regression:
Here, I ran a ridge regression using a range of 74 to 76
Optimal alpha: 75.15789473684211
Training R-squared score: 0.7358359935087796
Testing R-squared score: 0.7351716161978512
While it offers an incredibly slight increase in R-squared values, the ridge regression is very similar to the previous R-squared values we have found.
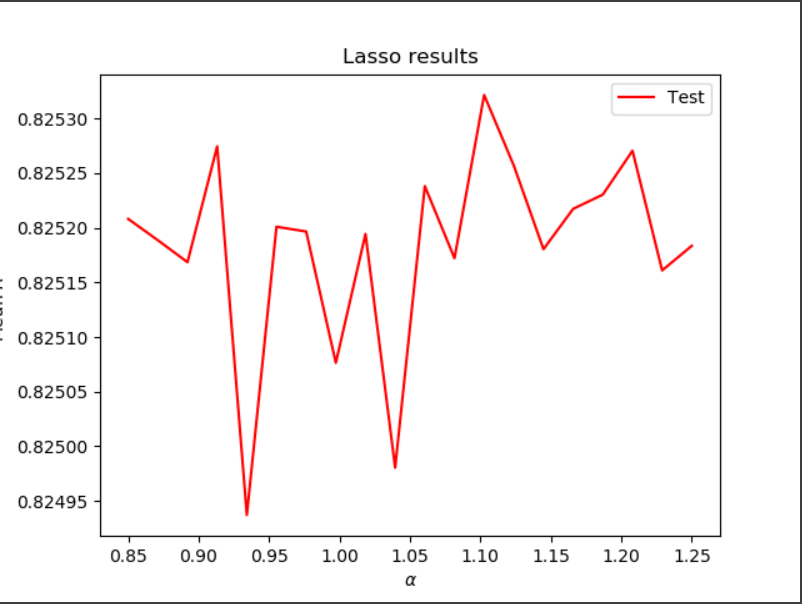
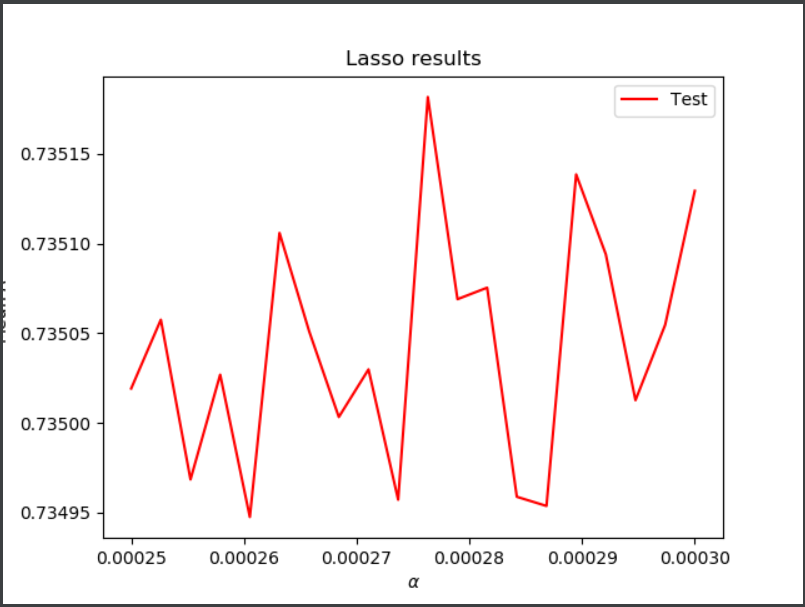
Lasso Regression:
Here, I ran a ridge regression using a range of 0.00025 to 0.0003
Optimal alpha: 0.0002763157894736842
Training R-squared score: 0.7358331609945438
Testing R-squared score: 0.7351816585744342
Here, I again got R-squared values that very closely matched my past findings. That being said, these values are very slightly less than those that I found for my ridge regression.
WealthI:
Linear Regression:
R-Squared training: 0.82583686585401
R-Squared testing: 0.825228216491869
R-Squared training after standardization: 0.8258275657271813
R-Squared testing after standardization: 0.8252730034174747
I was not able to get the MSE for WealthI, and as a result have not included it. It was much too high when I calculated it, and I could not figure out how to fix this error. In class, however, the Professor announced that this was okay.
The way that the r-squared values changed respectively to those for wealthI is substantial, and they are a significant increase. Comparing the R-squared values before versus those after standardization yields an incredibly small difference.
Again, the individual correlations changed greatly as a result of standardization.
Before standardization: [ 2.31986195e+03 1.08192000e+03 -5.08892487e+01 6.53283809e+03 3.17688859e+03 4.03623951e+03 -9.96051610e+03 1.12302854e+04 1.02336910e+04 -1.62924258e+04 -1.71918653e+04 -6.04206999e+03 2.08751277e+04 -9.31120042e+03 2.41734580e+04 1.34930387e+04 -6.80151578e+03 -1.25300357e+04 -9.08909982e+03 5.48192929e+03 7.99367502e+03 -1.34756043e+04 1.74439055e+04 3.27144540e+04 5.76665872e+03 3.89473708e+02 2.46689944e+03 -1.29356339e+04 -1.29054696e+04 -2.77376917e+04 -2.95652191e+04 -2.65078796e+04 2.29944393e+04 -3.88963009e+03 3.17656932e+04 4.00606955e+04 3.66535576e+04 9.64026616e+03 4.80974344e+04 9.98177625e+03 -1.07028288e+04 -9.12002749e+03 -1.86232403e+04 -4.61832386e+04 -3.14138344e+04 -7.19146447e+03 -1.55796604e+04 -5.61943537e+03 -3.46563978e+04 3.46563978e+04 -3.20570735e+04 3.20570735e+04 1.51485651e+03 5.89549456e+04 2.36376276e+04 9.41611219e+03 -6.81569745e+04 -2.53665673e+04 -2.24372689e+04 2.24372689e+04]
After standardization: [ 8.64356381e+03 5.42291563e+02 -9.95378291e+02 5.39229166e+03 1.15179252e+15 1.35388632e+15 1.20220915e+15 1.23684778e+15 1.32140360e+15 1.23447592e+15 1.23209826e+15 1.37002573e+15 1.35369490e+15 1.33514720e+15 1.81518307e+15 1.57964503e+15 1.19571401e+15 1.17389243e+15 1.28023609e+15 2.36970417e+15 3.58679464e+15 3.88533640e+15 4.36317659e+14 4.38677953e+14 8.00371996e+14 9.31238104e+14 4.80593116e+15 2.36933029e+15 9.97670192e+14 1.48540752e+15 4.21847600e+15 3.12005422e+14 5.18451163e+14 8.21809227e+14 1.06073999e+15 9.21536993e+14 4.02313198e+15 1.55335251e+15 7.50697115e+14 2.90186498e+14 6.06626995e+15 3.66471785e+15 3.95673898e+15 7.66789308e+15 3.14741587e+14 4.55999075e+14 2.89124405e+15 5.96855742e+14 -3.24300135e+14 -3.24300135e+14 -1.04770253e+15 -1.04770253e+15 -2.85286179e+14 -1.33040373e+14 -2.59305518e+14 -5.60852493e+15 -5.64632904e+15 -8.22809740e+14 -9.47022335e+14 -9.47022335e+14]
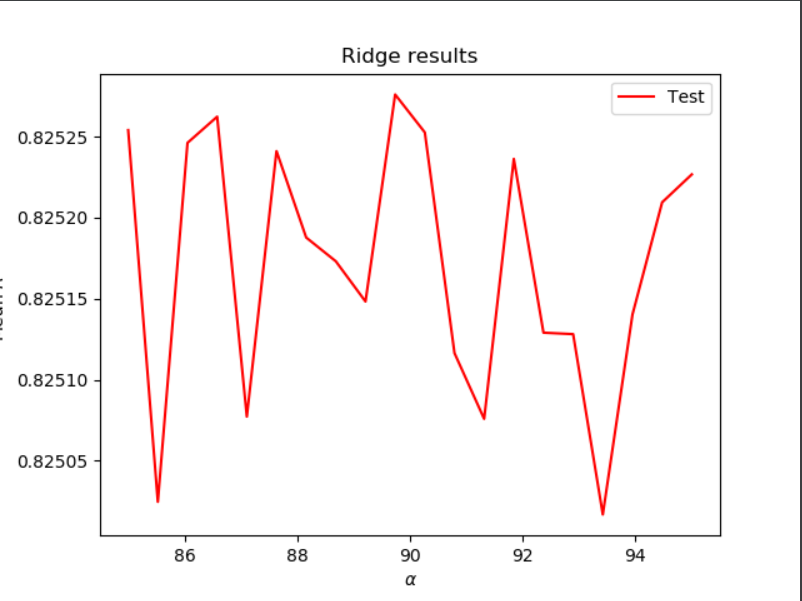
Ridge Regression:
Here, I ran a ridge regression using a range of 85 to 95
Optimal alpha: 89.73684210526315
Training R-squared score: 0.8258370223066807
Testing R-squared score: 0.8252759985555489
The ridge regression produced a small increase in r-squared values compared to the values for the Linear regression.
Lasso Regression:
Here, I ran a ridge regression using a range of 0.85 to 1.25
Optimal alpha: 1.1026315789473684
Training R-squared score: 0.8258373086089591
Testing R-squared score: 0.8253215556264802
The lasso regression created r-squared values that were slightly larger than those for the ridge regression and linear regression, but notably so.
Which of the models produced the best results in predicting wealth of all persons throughout the smaller West African country being described? Support your results with plots, graphs and descriptions of your code and its implementation. You are welcome to incorporate snippets to illustrate an important step, but please do not paste verbose amounts of code within your project report. Alternatively, you are welcome to provide a link in your references at the end of your (part 1) Project 5 report.
Overall, all of the regressions utilizing ‘wealthI’ were better at predicting wealth than any of those utilizing ‘wealthC’. This is because all of the ‘wealthI’ models possessed notably higher r-squared values than any of the ‘wealthC’ models.
When it comes to deciding which model to use from ‘wealthI’, the lasso regression is the best. This is because, at its optimal alpha value of 1.1026315789473684, it is has an r-squared testing value of 0.8253215556264802, whereas the ridge regression’s highest r-squared testing value is 0.8252759985555489. This can be seen in the plot for wealthI’s lasso regression, where there is a point that surpasses .82530 on the plot, whereas the points for the plot of the ridge regression model never do the same.
This being said, each of the three models for ‘wealthI’ were very similar to each of the other two models in terms of r-squared value, and the same goes for those of ‘wealthC’. So while the lasso regression model from ‘wealthI’ is the best predictor at determining wealth, it is only the best by a very small amount when compared to the other models of ‘wealthI’.
Ridge regression for Wealth C:
Ridge regression for Wealth I:
Lasso Regression for Wealth C:
Lasso Regression for Wealth I: